
TL;DR
Human-in-the-Loop ist nicht automatisch sicher. Ob eine KI-Aktion einen Menschen braucht, hängt an zwei Achsen: wie groß der mögliche Schaden wäre (Blast Radius) und wie lange ein Mensch für die Beurteilung braucht (Prüfaufwand). Daraus ergeben sich vier Muster:
- Autonom bei niedrigem Risiko und schneller Prüfbarkeit
- LLM-as-Judge bei niedrigem Risiko und hohem Prüfaufwand
- Human-in-the-Loop bei hohem Risiko und schneller Prüfbarkeit
- Mensch entscheidet, KI unterstützt bei hohem Risiko und hohem Prüfaufwand
Lange ging es bei KI-Features vor allem um Chat: Ein Modell antwortet, ein Mensch liest. Das Gewicht der Antwort endete beim Mausklick.
Das ändert sich gerade. KI-Features schreiben Tickets, verschicken E-Mail-Drafts, kategorisieren Schadensmeldungen, lösen Rückerstattungen aus, generieren Inhalte, die direkt an Nutzer gehen. Aus antworten wird handeln, und aus handeln wird oft auch generieren. Bei jedem dieser Schritte entsteht dieselbe Frage: Muss da eigentlich noch ein Mensch zwischen der KI und dem stehen, was sie tut oder produziert?
In AI Systems Architecture habe ich Action Safety als viertes Prinzip neben Contract, Evals und Observability definiert. Dort ging es darum, dass ein System klare Grenzen braucht, was es autonom darf. Jetzt wird es konkret: welche Art von Freigabe, durch wen, und wie oft.
Auf diese Frage gibt es drei naheliegende Antworten. Jede ist für sich sinnvoll. Als alleinige Lösung scheitert jede.
Irrtum 1: Einfach blind vertrauen
Die erste Antwort lautet: Wozu überhaupt prüfen? Das Modell ist gut, die Benchmarks sind beeindruckend, der Demo-Call lief sauber. Feature deployen, fertig.

Wie man darauf kommt. Es ist schnell und billig. In der Demo funktioniert alles. Und ehrlich gesagt: In neun von zehn Fällen geht es auch in Produktion gut. Das reicht, um eine ganze Weile wie eine Erfolgsgeschichte auszusehen.
Woran es scheitert. Die zehnte Antwort macht den Unterschied. Das Modell ist probabilistisch, nicht deterministisch. Es schreibt Code, der syntaktisch korrekt ist und semantisch daneben. Es löst Refunds für Bestellungen aus, die es nicht gibt. Es löscht Produktionsdaten, weil ein Agent-Loop entschieden hat, jetzt sei ein guter Moment zum Aufräumen. Je höher der Blast Radius einer Aktion, desto teurer wird genau dieser eine Prozentsatz.
Blind vertrauen skaliert, solange nichts schiefgeht. Wenn es schiefgeht, steht niemand da, der es auffängt. Oder es überhaupt mitbekommt.
Irrtum 2: LLM-as-a-Judge als Allheilmittel
Die nächste naheliegende Antwort: Wenn ein Modell Fehler macht, lass ein zweites Modell es prüfen. Im Fachjargon heißt das LLM-as-a-Judge, ein Sprachmodell bewertet den Output eines anderen. Automatisch, skalierbar, billig im Vergleich zu Menschen.

Wie man darauf kommt. Es klingt sauber. Das Modell, das die Arbeit macht, bekommt eines, das aufpasst. Zwei sind besser als eins. Das skaliert auch auf Millionen von Outputs, die ein Mensch nie lesen würde. Und für bestimmte Fragen funktioniert es wirklich gut.
Woran es scheitert. LLMs haben überlappende Blind Spots. Wenn Modell A einen bestimmten Typ Fehler macht, übersieht Modell B ihn oft ebenfalls, weil beide auf ähnlichen Daten trainiert wurden, ähnliche Biases haben, ähnliche Muster missachten. Dazu kommt: Ein Judge, der “pass/fail” klassifiziert, ist nur so gut wie die Rubrics, nach denen er bewertet. Die zu definieren ist selbst wieder Arbeit, und jemand muss irgendwann prüfen, ob die Rubrics stimmen.
LLM-as-a-Judge ist ein wertvolles Werkzeug. Als alleiniges Sicherheitsnetz ist es Scheinsicherheit. Zwei probabilistische Systeme in Reihe werden nicht deterministisch, sie produzieren nur einen anderen probabilistischen Fehler.
Irrtum 3: Alles von Menschen prüfen lassen
Bleibt die klassische Antwort: Ein Mensch dazwischen. Human-in-the-Loop. Vor jeder Aktion der KI gibt ein Mensch frei. Auf dem Papier sauber, rechtlich verantwortbar, menschliche Urteilskraft als letzte Instanz.

Wie man darauf kommt. Es klingt nach Kontrolle. In Compliance-Gesprächen ist “Wir haben Human-in-the-Loop” inzwischen der Standardsatz, wenn es um Verantwortbarkeit von KI-Features geht. Ein Mensch trägt die Verantwortung, nicht die Maschine. Und für bestimmte Entscheidungen ist das genau richtig.
Woran es scheitert. Wir kennen das alle. Wenn wir zu oft klicken müssen, klicken wir irgendwann zu schnell. Den Cookie-Banner, den man wegklickt, bevor die Augen den Text erfasst haben. Die AGBs, die keiner mehr liest. Die Confirm-Dialoge, die zum Muskel-Reflex geworden sind. Die GitHub-PR-Review mit zwanzig Files, bei der Approve nach dem fünften File zur Routine wird.
In Krankenhäusern klicken Ärztinnen und Ärzte 90 bis 95 Prozent der Arzneimittel-Interaktionswarnungen weg, bevor sie sie gelesen haben.1 Teilweise mit gutem Grund, weil viele Alerts klinisch irrelevant sind. Aber genau darin liegt das Problem. Wenn neun von zehn Warnungen Rauschen sind, trainiert das System den Menschen, nicht mehr hinzuschauen. Wenn dann die eine echte Warnung kommt, geht sie denselben Weg.
Wer glaubt, KI-Approval-Dialoge seien davon ausgenommen, hat sich selbst nie dabei beobachtet. Automation Complacency ist der akademische Begriff. Ich nenne es, was es für mich ist: Schauspiel.
Drei Tauben in einer Box
1978 begann die US-Küstenwache ein Projekt namens Sea Hunt. Drei Tauben wurden in eine Box unter einem Rettungshelikopter geschnallt, trainiert auf die Farbe Orange. Bei Testflügen entdeckten die Tauben das Ziel beim ersten Überflug in 90 Prozent der Fälle. Menschliche Crew-Mitglieder kamen auf 38 Prozent. Nach drei Stunden Flug über endloses Wasser waren die Menschen erschöpft. Die Tauben nicht.2
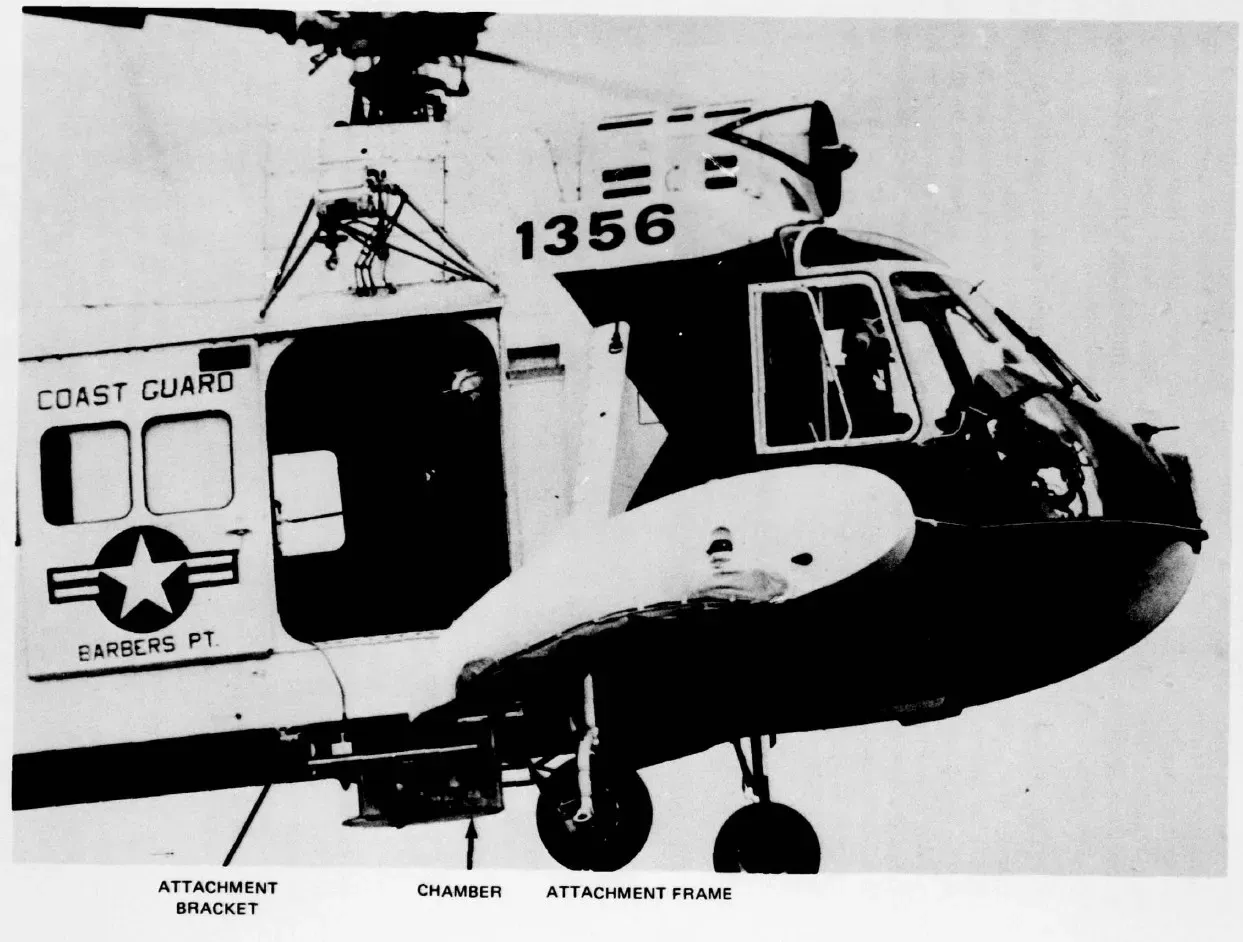
Die Geschichte ist keine Studie, sie ist ein Bild. Die Pointe ist nicht, dass Tauben klüger sind oder Menschen grundsätzlich schlecht urteilen. Die Pointe ist: Viele Approval-Dialoge stellen den Menschen genau dort auf, wo die Taube besser wäre. Am Fließband, bei der hundertsten gleich aussehenden Entscheidung.
Die zwei Achsen
Die drei Antworten von oben haben alle etwas Richtiges. Blind vertrauen ist okay für harmlose Dinge. LLM-as-a-Judge ist nützlich, wenn man die Grenzen kennt. Menschen sind für manche Aktionen unverzichtbar. Nur als alleinige Antwort scheitert jede einzelne.
Die eigentliche Frage wird in den meisten Projekten überhaupt nicht gestellt: Welches Werkzeug gehört an welche Stelle? Und wenn doch, läuft sie oft nur auf eine Dimension hinaus. Wie gefährlich ist die Aktion? Das greift zu kurz. Es gibt eine zweite Achse, die in den meisten Governance-Diskussionen fehlt. Wie lange braucht ein Mensch, um das Ergebnis überhaupt zu beurteilen? Eine Refund-Freigabe ist in drei Sekunden prüfbar: Bestellnummer, Kundenidentität, Betrag, Knopf. Ein generierter Songtext oder ein KI-Business-Plan nicht.

Die beiden Achsen spannen vier Szenarien auf. Die Werkzeuge sind in jedem anders, und keines der drei Patterns von oben passt überall.
Szenario 1: Autonom
Niedriger Blast Radius, niedriger Prüfaufwand. Ein Lookup, eine Suche, eine Klassifikation mit geringer Konsequenz. Hier bremst jeder Approval-Dialog nur. Schlimmer: Jeder unnötige Approval-Schritt drückt die Approve-Rate nach oben und damit die Aufmerksamkeit für die wirklich wichtigen Momente nach unten.

Szenario 2: Human-in-the-Loop
Hoher Blast Radius, niedriger Prüfaufwand. Refund auslösen, Account löschen, Production-Deployment. Die Entscheidung ist in wenigen Sekunden prüfbar, der Fehler wäre teuer. Das ist das klassische Human-in-the-Loop-Territorium und im Grunde das einzige Szenario, in dem ein Approval-Dialog seine volle Berechtigung hat.
Ruben Vitt zeigt dazu konkrete Beispiele, wie man solche Dialoge so baut, dass der Mensch wirklich prüft und nicht nur durchklickt.
Was dabei oft unterschätzt wird: die Qualität der Interaktion selbst. Ein Dialog, der sich wegklicken lässt, wird weggeklickt. Ein Dialog, der eine kleine Mit-Arbeit verlangt, eine kurze Begründung, einen manuell eingetippten Betrag, ein gezieltes Markieren von Details, zwingt den Menschen zum Nachdenken. Die weiteste Form dieses Gedankens hat Google mit reCAPTCHA vorgemacht.
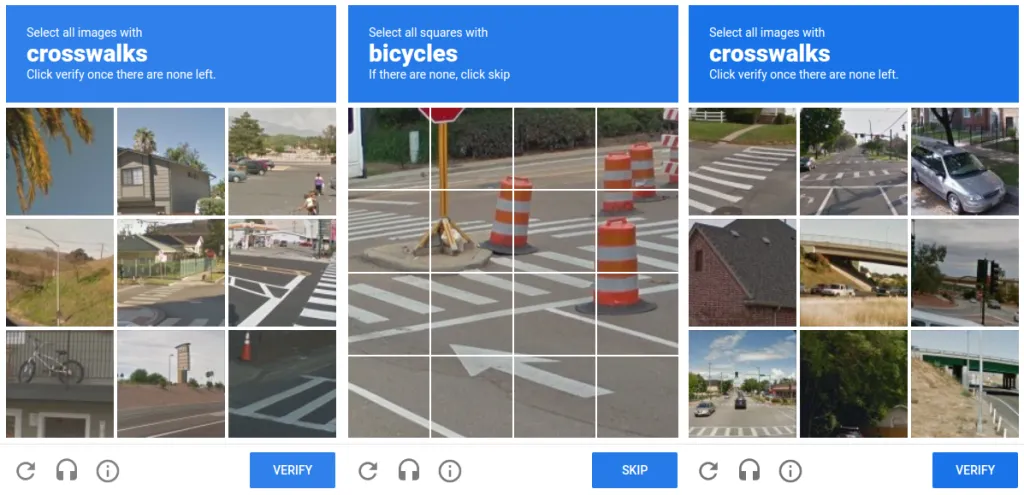
“Klick auf alle Bilder mit einem Zebrastreifen” war keine Gatekeeping-Entscheidung, sondern echte Labeling-Arbeit für die Straßenschild- und Hausnummern-Erkennung. Der Mensch war im Loop, ohne es zu wissen, und hat dabei tatsächlich gearbeitet, nicht nur bestätigt. Wenn jeder Klick zählt, klickt niemand blind. Gute UX und ein Schuss Gamification sind hier keine Spielerei, sondern Teil der Sicherheitsarchitektur.

Szenario 3: LLM-as-Judge
Niedriger Blast Radius, hoher Prüfaufwand. Ein generierter Songtext, eine E-Mail-Antwort, ein zusammenfassender Report. Der Mensch müsste den Text komplett lesen oder drei Minuten Audio anhören, um urteilen zu können. Bei tausend Outputs pro Tag geht das nicht.
Hier hilft kein Approval-Dialog. Kontrolle muss anderswo sitzen, bevor der Output entsteht oder nachdem er da ist. Und hier ist LLM-as-Judge tatsächlich ein sinnvolles Werkzeug, weil es nicht als einzige Instanz steht, sondern als eine von mehreren Schichten.
Ein Beispiel aus meiner eigenen App: VerseLoop hilft Menschen, Bibelverse auswendig zu lernen. Ein Feature erzeugt dazu Lern-Lieder per KI. Der Songtext ist nur ein Schritt davon, danach kommt die Audio-Generierung mit Stil-Tags. Bei mehreren tausend möglichen Custom-Songs pro Monat kann ich mir als Solopreneur weder jeden Text durchlesen noch jedes Lied anhören. Stattdessen kombiniere ich mehrere Schichten: einen engen Prompt-Contract, automatische Post-Checks gegen den Quelltext und gezielte Stichproben beim Audio.

Szenario 4: Mensch entscheidet, KI unterstützt
Hoher Blast Radius, hoher Prüfaufwand. Eine KI bereitet eine Business-Entscheidung mit viel Kontext vor, und der Mensch müsste tief einsteigen, um sauber freizugeben. Hier gibt es keine elegante, skalierende Lösung, und deswegen ist die ehrlichste Frage: Soll die KI hier wirklich entscheiden oder handeln, oder reicht es, wenn sie den Menschen bei seiner Entscheidung unterstützt?
Der Unterschied ist wesentlich. Eine KI, die Fakten zusammenträgt, Quellen markiert und Optionen sortiert, ist ein gutes Werkzeug für den Menschen. Eine KI, die die Entscheidung selbst vorwegnimmt und der Mensch nur noch absegnet, verschiebt den Aufwand nur an eine Stelle, wo er nicht mehr ankommt. Das empfohlene Muster in diesem Quadranten ist deshalb umgedreht: Der Mensch entscheidet, die KI liefert zu. Augmentation statt Automation.
Wer trotzdem die KI am Hebel sitzen lässt, kann das Volumen senken, indem nur die wirklich schwierigen Fälle zum Menschen durchgelassen werden. Das Interface so bauen, dass der Reviewer schnell Kontext aufbaut. Rotation verankern, damit niemand in dieselbe Routine rutscht. Aber den kognitiven Aufwand selbst kann man nicht wegoptimieren. Echte Prüfung braucht Zeit, und diese Zeit lässt sich nicht multiplizieren.

Der Mensch ist manchmal der schlechtere Classifier
Ein Beispiel aus meinem eigenen Terminal. Claude Code hat gemessen, dass Nutzer 93 Prozent aller Freigabe-Dialoge bestätigen. Ich bin einer dieser Nutzer, und als ich die Zahl gelesen habe, habe ich mich selbst ertappt. Ja, ja, ja, weiter.
Anthropic hat darauf mit einem Auto Mode reagiert. Ein vorgeschalteter Classifier entscheidet vor jedem Tool-Call: Darf das Modell hier autonom weitermachen, oder gehört das vor einen Menschen? Im Grunde sortiert der Classifier jede einzelne Aktion in einen der vier Quadranten ein, Fall für Fall. Bewusst gewählt ist dabei eine False-Negative-Rate von 17 Prozent. Wer jeden Grenzfall zum Menschen eskaliert, landet wieder im Ja-Ja-Ja. Ein paar durchrutschende Grenzfälle sind der Preis dafür, dass bei den echten Eskalationen noch jemand hinschaut.
Ich nutze den Auto Mode inzwischen so gerne, dass ich ehrlich sagen kann: Er ist sicherer als mein manueller Modus. Nicht weil das Modell perfekt wäre, sondern weil ich in monotonen Approval-Flows systematisch unaufmerksam werde. Strukturell liegt er zwischen den Irrtümern von oben: weder blind autonom noch alles vom Menschen prüfen lassen, sondern eine bewusste Zuteilung pro Aktion.
Der größere Punkt dahinter: Bei Claude Code übernimmt ein Classifier diese Zuordnung zur Laufzeit. In den meisten Systemen fällt sie vorher, am Whiteboard, und trifft jeder von uns. AI Systems Architecture heißt genau das: die Entscheidung, welche Aktion in welchen Quadranten gehört, bewusst und früh treffen. Wer sie nicht trifft, bekommt sie zufällig zugeteilt, meist zuungunsten der Sicherheit oder der Geschwindigkeit oder beider.
Das ist keine Abschaffung von Human-in-the-Loop, sondern eine Neuzuteilung. Der Mensch kommt, wenn es wirklich brenzlig wird. Den Rest macht eine Taube.
Zwei Fragen, jedes Mal
Human-in-the-Loop ist keine Compliance-Aussage, sondern eine Architektur-Entscheidung. Wer die Zuordnung zu den Quadranten nicht bewusst trifft, überlässt sie dem Zufall. Oder schlimmer: dem Compliance-Reflex.
Bevor das nächste “Wir haben Human-in-the-Loop” aus einem Management-Deck rollt, lohnen sich zwei Rückfragen:
- Wie viele Approvals pro Person pro Tag?
- Wie verhindert ihr, dass euer Team nur noch abnickt?
An den Antworten lässt sich ablesen, ob hier Kontrolle gebaut wurde oder ein Dialog, der sich gut anfühlt.
Weiterlesen:
Ruben Vitt arbeitet in Approval ist kein UX-Bug das Bauprinzip für Governance-Gates detailliert aus. Wer die technische Seite vertiefen will, Policy Gates, SDK-Patterns, Audit-Trails, ist dort richtig.
Anthropic beschreibt in Claude Code Auto Mode, wie der zweistufige Classifier Approval-Fatigue adressiert und warum eine akzeptierte False-Negative-Rate kein Designfehler ist.
Footnotes
-
Meta-Analyse zu Drug-Drug-Interaction-Alerts in Clinical Decision Support Systems, Override-Rate bei 90 Prozent, 95-Prozent-Konfidenzintervall 85-95 Prozent: Felisberto et al., Override rate of drug-drug interaction alerts in clinical decision support systems: A brief systematic review and meta-analysis (Health Informatics Journal, 2024). Vertiefend: Appropriateness of Overridden Alerts in Computerized Physician Order Entry: Systematic Review (JMIR Medical Informatics, 2020). ↩
-
That Time the U.S. Coast Guard Had a Pigeon-Powered Sensor, basierend auf dem Project Sea Hunt Study 1978-83 des US-Verteidigungsministeriums. ↩