
Seit Mitte März ist das 1M-Token-Kontextfenster für Opus 4.6 und Sonnet 4.6 Standard. Kein Beta-Header mehr, kein Aufpreis für lange Kontexte. Eine Million Tokens, einfach so.
Eine Million Tokens. Das ist fast einmal die komplette Bibel. Oder drei Bände “Herr der Ringe” plus “Der Hobbit”, und da bleibt sogar noch Platz übrig. Das klingt nach einer beeindruckenden Zahl, ist aber erstmal nur Quantität. Was die Sache interessant macht, sind die Retrieval-Zahlen.
Die Nadel im Heuhaufen
Ein großes Kontextfenster bringt wenig, wenn das Modell darin nichts wiederfindet. Genau das war bisher das Problem. Gemessen wird das mit Benchmarks wie MRCR (Multi-turn Retrieval with Contextual Reasoning): Man versteckt spezifische Informationen in hunderttausenden Tokens Rauschen und prüft, ob das Modell sie gezielt wiederfindet - die Nadel im Heuhaufen, aber mit steigendem Schwierigkeitsgrad.
Sonnet 4.5 hatte zwar ein Millionen-Token-Fenster, aber die Fähigkeit, darin gezielt Informationen wiederzufinden, lag bei etwa 14%. Weniger als eins zu sieben. Praktisch unbrauchbar.
Opus 4.6 liegt bei 78% (Anthropics eigener Benchmark, also mit der gebotenen Vorsicht zu lesen - aber die Größenordnung deckt sich mit dem, was ich in der Praxis sehe).
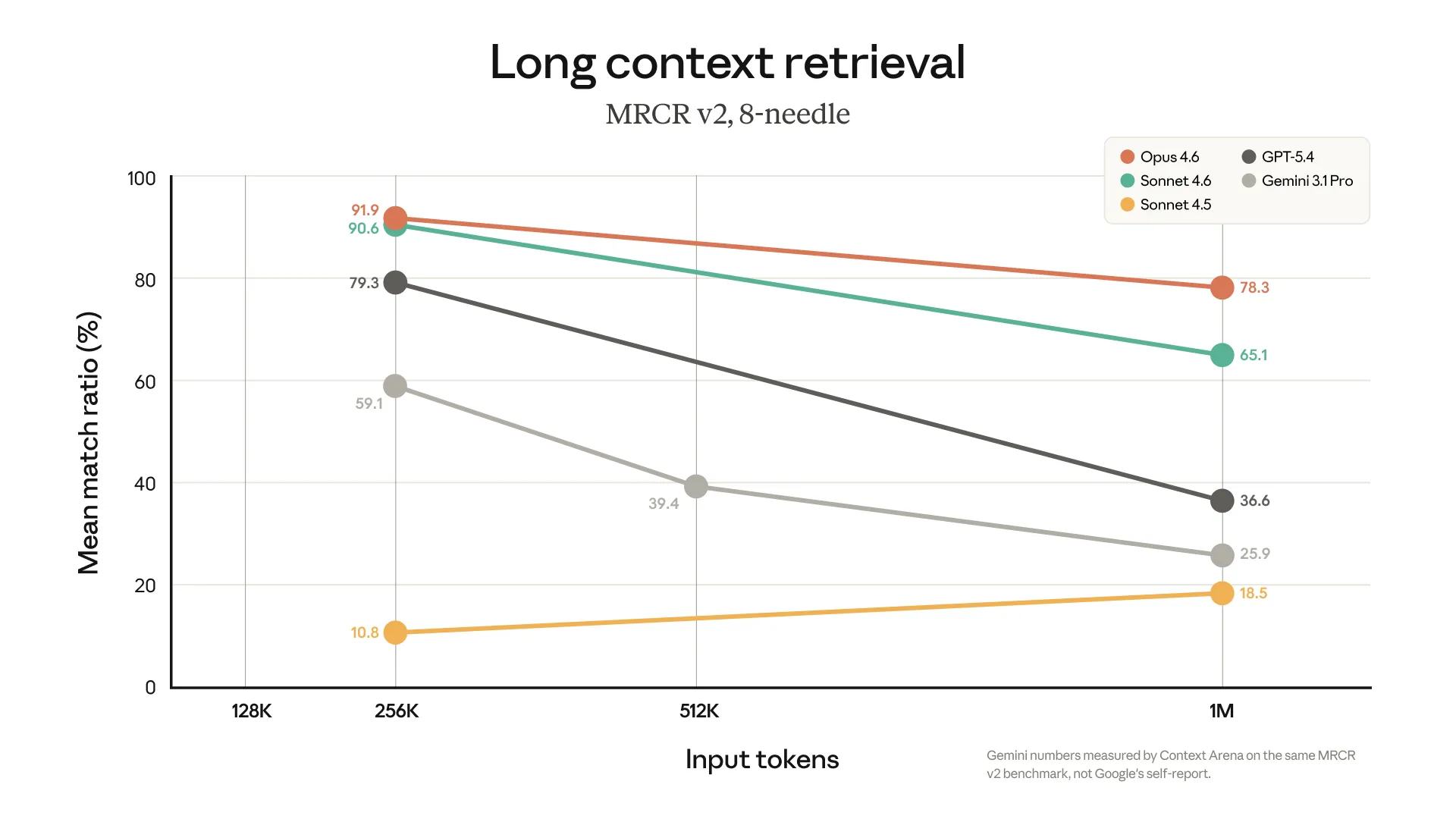
Zum Vergleich: Gemini kommt bei 1M Tokens auf rund 26%, GPT 5.4 auf 37%. Der Sprung von Opus ist kein inkrementelles Update. Es ist der Unterschied zwischen einem Modell, das 50.000 Zeilen Code halten kann, und einem, das 50.000 Zeilen Code hält und weiß, was auf jeder einzelnen steht.
Was sich für mich verändert hat
Ich nutze seit Monaten Spec-Driven Frameworks für meine Arbeit. Tools wie BMad zerlegen Epics in kleine, beherrschbare Stories, damit das Modell nicht mittendrin abbricht. Bei 200.000 Token Standardkontext war das überlebenswichtig. Man ist ständig in Compactions1 reingelaufen, Kontext ging verloren, und ab einem gewissen Punkt hat man komplexe Aufgaben gar nicht erst versucht.
Mit 1M Tokens sieht das anders aus. Ein Epic, das vorher zehn bis fünfzehn Stories brauchte, bearbeite ich jetzt mit zwei bis drei. Der Agent zieht das in einem Durchlauf durch, ohne Compaction, ohne Kontextverlust. Er ist nicht schneller geworden. Er kann einfach mehr auf einmal im Blick behalten.
Das ist keine Effizienzsteigerung. Ich arbeite auf einer anderen Ebene als noch vor drei Monaten.
Subtask, Task, Epic
In den Trainings für Agentic Software Engineering beschreibe ich seit einer Weile, wie sich die Delegation an KI-Agenten entwickelt hat. Anfang 2025 haben die meisten auf Subtask-Ebene gearbeitet: einzelne Funktionen generieren, einzelne Bugs fixen, Autocomplete mit Kontext. Dann kam die Task-Ebene: “Implementiere dieses Feature basierend auf der Spec.” Der Agent arbeitet eigenständig, ich prüfe das Ergebnis.
Jetzt bin ich bei Epics angekommen. Zusammenhängende Arbeitspakete, die früher Tage gebraucht hätten. Und das funktioniert, weil der Agent nicht nach 30 Minuten den Faden verliert.
Frameworks müssen mitziehen
Die Toolchains und Workflows, die wir um diese Modelle herum bauen, sind auf die Limitierungen der Vorgänger optimiert. Kleine Chunks, klare Übergaben, manuelles Routing zwischen Schritten. Das war bei 128K oder 200k-Kontexten die richtige Strategie.
Bei 1M Tokens ist es wie Ferrari fahren im ersten Gang.
Ich habe angefangen, meine Workflows und Prompts umzubauen. Größere Stories, weniger Zerlegung, mehr Vertrauen darin, dass das Modell komplexe Zusammenhänge über längere Strecken halten kann. Das Ergebnis: schneller und besser gleichzeitig, weil der Agent den Gesamtkontext sieht statt isolierter Fragmente.
Je besser das Modell wird, desto mehr muss ich loslassen. Weniger kleinteilige Instruktionen, mehr Arbeit auf der Zielebene. Beschreiben, was am Ende stehen soll, nicht jeden Schritt vorschreiben. Das zieht sich durch das ganze Jahr, und ich gewöhne mich immer noch daran.
![]()
Die Schattenseite
Die Sache hat einen Haken. Diese Retrieval-Qualität bei dieser Kontextgröße liefert aktuell nur Anthropic. Wer anfängt, auf Epic-Ebene zu arbeiten, bindet sich an ein Ökosystem. Kein anderes Modell kommt bei 1M Tokens auch nur in die Nähe dieser Zahlen. Das ist kein theoretisches Problem. Es bedeutet: Wenn Anthropic die Preise ändert, die API drosselt oder das Modell in eine Richtung entwickelt, die nicht zu meinem Workflow passt, habe ich ein Problem.
Trotzdem: Der Produktivitätssprung ist so groß, dass ich diesen Trade-off aktuell bewusst eingehe.
Mehr als Code
Was mich am meisten beschäftigt: Der gleiche Effekt greift überall dort, wo ich mit komplexem Material arbeite. Buchprojekte, Kursentwicklung, Strategieplanung. Vieles davon ist noch nicht spruchreif, aber die Richtung ist klar.
Ausblick: Mythos
In der Community kursieren Leaks zu Anthropics nächstem Modell, Codename “Mythos”. Trainiert auf Nvidias neuen GB300-Chips, nach allem was man hört deutlich größer als die aktuelle Generation. Belastbare Fakten gibt es noch nicht, nur Berichte von Security-Researchern, die erstaunliche Ergebnisse beschreiben.
Wenn auch nur die Hälfte davon stimmt, steht der nächste Sprung bevor. Was genau das für die tägliche Arbeit bedeutet, weiß noch niemand. Ich weiß nur: Wer seine Workflows nicht mal an die aktuellen Möglichkeiten angepasst hat, lässt beim nächsten Sprung noch mehr Potenzial liegen.
Footnotes
-
Compaction ist der Mechanismus, mit dem KI-Agenten wie Claude Code ihren Kontext zusammenfassen, wenn das Kontextfenster voll wird. Dabei geht zwangsläufig Information verloren - Details, die der Agent vor einer Stunde noch kannte, sind danach weg. ↩