
Lokale LLMs im Praxistest: Was Open-Weight-Modelle heute wirklich leisten
Ein praxisnaher Vergleich zwischen lokalen Open-Weight-Modellen und Cloud-Frontier-Modellen
Vorurteile vs. Realität
Immer mehr Teams wollen LLMs einsetzen - für Coding, aber auch für datenschutzsensitive KI-Features in ihren Produkten. Nicht alles darf in die Cloud. Lokale Modelle versprechen eine Alternative. Aber taugen die was?
“Lokale LLMs sind zu langsam.” “Die Qualität von lokalen Modellen ist auf Niveau von GPT-3.” “Open-Weight-Modelle laufen nur auf Servern mit vielen GPUs.” Diese Sätze höre ich regelmäßig. Sie spiegeln ein Bild wider, das heute überholt ist.
In den letzten 18 Monaten hat sich bei lokalen LLMs viel getan. Der Trend geht zu spezialisierten MoE-Modellen (Mixture of Experts): Coding-Modelle wie Qwen3-Coder oder Devstral bündeln domänenspezifisches Wissen in kompakten Architekturen. Die MoE-Technik aktiviert nur einen Bruchteil der Parameter pro Token - das macht sie schnell trotz nominell hoher Parameterzahl. Diese Modelle sind Open-Weight1 und laufen auf Consumer-Hardware. Quantisierungstechniken wie 4-bit GGUF2 oder MLX3 machen es möglich, ein 30B-Modell auf einem MacBook laufen zu lassen.
Meine Hauptmotivation für lokale Modelle sind Datenschutzbedenken. Persönliche Daten und Code, der nicht in die Cloud darf: Kundenprojekte mit NDA, proprietäre Algorithmen, sensible Geschäftslogik. Es gibt viele Gründe, warum Quellcode und Daten das eigene Netzwerk nicht verlassen sollte.
Aber wie gut sind lokale LLMs nun wirklich? Dafür habe ich mir (wie viele andere) einen eigenen kleinen Benchmark gebaut (Benchmark-Report). Warum? Die üblichen Benchmark-Grafiken sind mir zu abstrakt. Wenn ein Modell 85,3% auf SWE-bench erreicht und ein anderes 87,1%, was bedeutet das für die tägliche Arbeit? Außerdem: Benchmarks messen nur die Qualität der Ergebnisse. Sie sagen nichts darüber, wie schnell ein Modell auf meinem Laptop läuft. Ob ein 30B-Modell 10 oder 100 Tokens pro Sekunde schafft, hängt auch von meiner Hardware ab, nicht vom Modell allein.
Deshalb mein Ansatz: Ich lasse alle Modelle mit dem gleichen Prompt eine kleine Kanban-Webapp entwickeln. Die Screenshots zeigen auf einen Blick, was funktioniert und was nicht. Und die Messdaten zeigen, wie lange es gebraucht hat und wie viele Ressourcen die Modelle verbraucht haben.
Die Daten erzählen eine Geschichte, die viele nicht erwarten: Lokale Open-Weight-Modelle haben aufgeholt. Cloud-Modelle haben weiterhin die Nase vorn, aber lokale Modelle sind eine echte Alternative, wo Cloud nicht gewünscht oder erlaubt ist.
Der Test
Alle Modelle bekommen den gleichen Prompt: eine Kanban-Board-Webapp in einer einzigen HTML-Datei. Die Aufgabe testet mehrere Disziplinen gleichzeitig: HTML, JavaScript, CSS, Drag & Drop und Persistenz. Das Ergebnis lässt sich visuell auf einen Blick bewerten.
Der Prompt
Create a fully functional Kanban board in a single HTML file
using vanilla JavaScript (no frameworks like react).
Requirements:
... (siehe Benchmarkseite) ...Die Ergebnisse
Der direkte Vergleich
| Modell | Typ | Tokens/s | Zeit | RAM | Kosten | Qualität |
|---|---|---|---|---|---|---|
| Gemini 3 Pro | Cloud | 122 | 72s | - | $0.11 | Sehr gut |
| Claude Opus 4.5 | Cloud | 103 | 84s | - | $0.22 | Sehr gut |
| GPT-5.2-Pro | Cloud | 23 | 413s | - | $1.58 | Sehr gut |
| GLM-4.7-Flash | Lokal (6bit) | 56 | 134s | 25 GB | - | Sehr gut |
| Qwen3-Coder-30B | Lokal (4bit) | 94 | 51s | 18 GB | - | Gut |
| Qwen3-4B-Thinking | Lokal (4bit) | 128 | 90s | 3 GB | - | Mittel |
| Devstral-Small | Lokal (4bit) | 33 | 67s | 14 GB | - | Mittel |
| GPT-OSS-120B | Lokal (4bit) | 79 | 31s | 64 GB | - | Schlecht |
Geschwindigkeit: Lokale Modelle sind schnell genug
Qwen3-Coder-30B generiert mit 94 Tokens pro Sekunde und braucht nur 51 Sekunden für das komplette Kanban-Board. Der Grund ist die MoE-Architektur: Nicht alle 30 Milliarden Parameter sind aktiv, nur etwa 3 Milliarden pro Token.
GLM-4.7-Flash ist mit 56 tok/s langsamer und braucht über zwei Minuten, liefert aber das beste Ergebnis.
Warum so schnell? LLM-Inferenz ist memory-bound: Bei jedem Token müssen die Modellgewichte aus dem Speicher gelesen werden. Die Tokens/Sekunde korrelieren direkt mit der Memory Bandwidth:
| Chip | Memory Bandwidth | Qwen3-Coder-30B (4-bit) |
|---|---|---|
| Apple M4 Max | 546 GB/s | 94 tok/s |
| Apple M3 Max | 400 GB/s | ~69 tok/s |
| NVIDIA DGX Spark | 273 GB/s | ~47 tok/s |
Ein MacBook Pro mit M4 Max ist für LLM-Inferenz fast doppelt so schnell wie der NVIDIA DGX-Spark mit 128 GB RAM. Das erklärt auch, warum Quantisierung so wirksam ist: Ein 4-bit-Modell braucht halb so viel Bandbreite wie ein 8-bit-Modell.
Qualität: Lokale Modelle liefern solide Ergebnisse
Cloud-Modelle wie Gemini 3 Pro setzen den Goldstandard: vollständige, fehlerfreie Implementierungen mit allen Features.
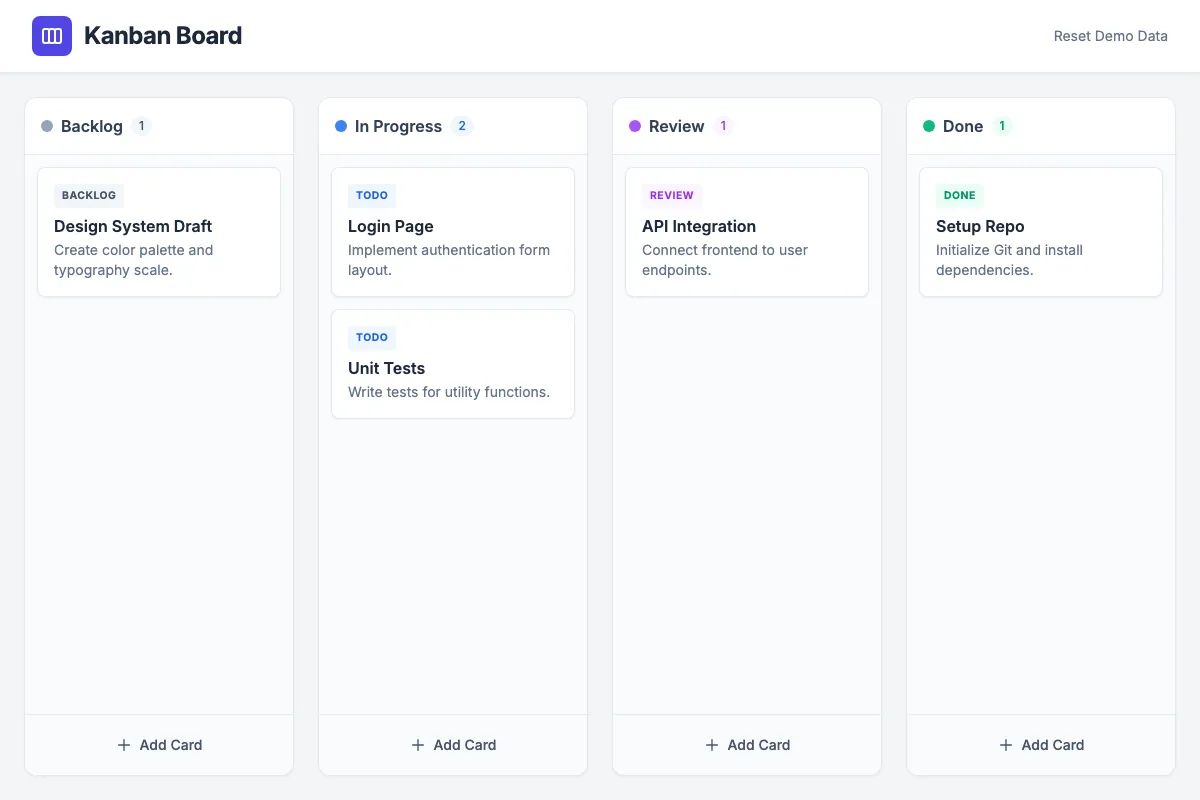 Gemini 3 Pro: Cloud-Referenz mit allen Features
Gemini 3 Pro: Cloud-Referenz mit allen Features
Die besten lokalen Modelle erreichen dieses Niveau. GLM-4.7-Flash (6bit) liefert korrektes Drag & Drop, funktionierende Persistenz und ein ansprechendes Design. Qwen3-Coder-30B (4bit) implementiert ebenfalls alle Features, mit gut kommentiertem Code:
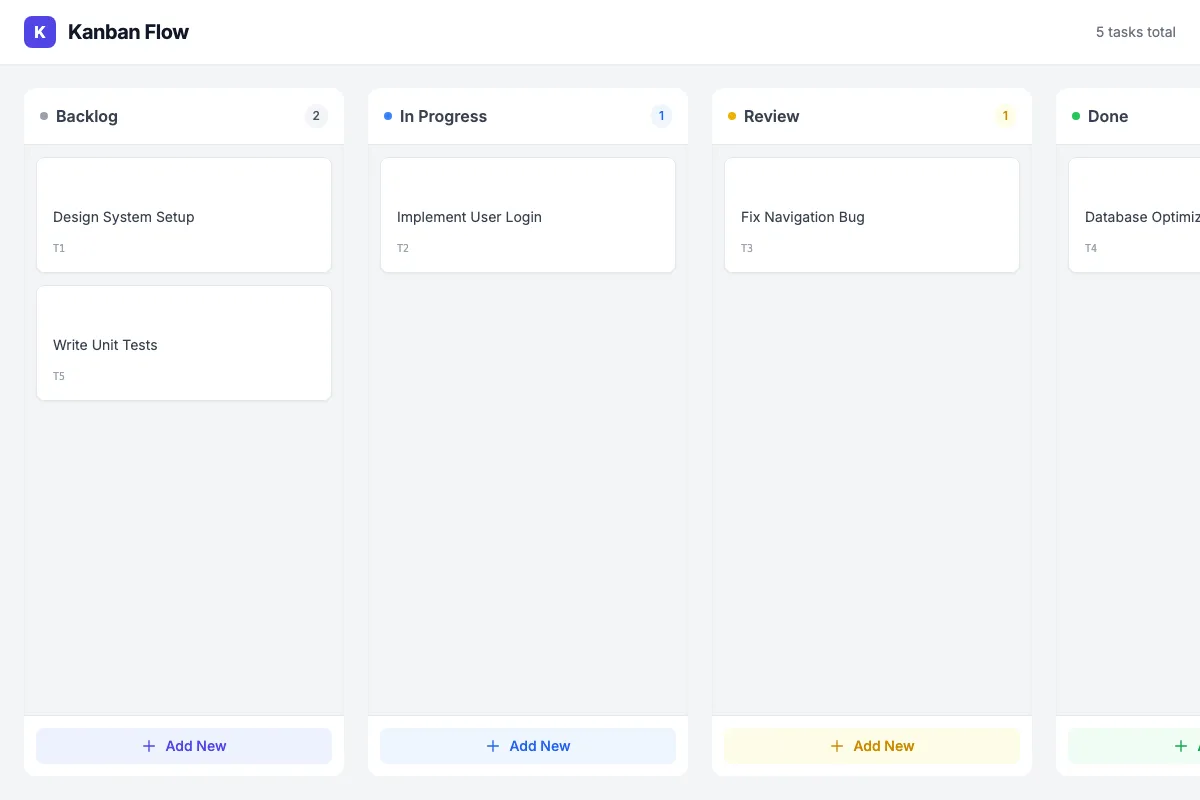 GLM-4.7-Flash (6bit): Erreicht Cloud-Niveau
GLM-4.7-Flash (6bit): Erreicht Cloud-Niveau
 Qwen3-Coder-30B (4bit): Solide Umsetzung mit ausführlichen Kommentaren
Qwen3-Coder-30B (4bit): Solide Umsetzung mit ausführlichen Kommentaren
Nicht alle großen Modelle überzeugen. GPT-OSS-120B zeigt, dass reine Parameterzahl nicht ausreicht:
 GPT-OSS-120B: Fehlerhafte Implementierung trotz 120B Parametern
GPT-OSS-120B: Fehlerhafte Implementierung trotz 120B Parametern
Die Grenzen kleiner Modelle
Nicht alle lokalen Modelle liefern brauchbare Ergebnisse. Modelle unter 7 Milliarden Parametern scheitern häufig. Liquid LFM2.5-1.2B liefert nur eine Grundstruktur ohne funktionierendes JavaScript. Gemma-3-4B produziert unvollständiges HTML. Sehr kleine Modelle (<3B) schaffen oft kein valides HTML.
Am besten funktionieren Modelle zwischen 20 und 40 Milliarden Parametern. Sie laufen auf High-End-Consumer-Hardware (32-64 GB RAM), liefern brauchbare Ergebnisse und sind schnell genug für interaktive Nutzung.
Überraschung: Kleine Thinking-Modelle
Das überraschendste Ergebnis kam von Qwen3-4B-Thinking. Dieses 4-Milliarden-Parameter-Modell nutzt Chain-of-Thought-Reasoning und generiert dabei über 12.000 Tokens - mehr als doppelt so viele wie Qwen3-Coder-30B.
Das Ergebnis liegt qualitativ unter den Spitzenreitern, kann aber mit deutlich größeren Modellen mithalten. Bei nur 3 GB RAM-Bedarf eine interessante Option für ressourcenbeschränkte Umgebungen.
Praktische Empfehlungen
Meine Empfehlung: GLM-4.7-Flash, falls genug RAM vorhanden ist (64 GB). Sonst Qwen3-Coder-30B.
GLM-4.7-Flash liefert die beste Qualität unter den lokalen Modellen und macht vor allem bei der Tool-Nutzung große Fortschritte. Qwen3-Coder-30B ist die beste Wahl für Systeme mit weniger RAM - gute Ergebnisse im Einzelaufruf, aber schwächer bei mehrstufigen Agenten-Workflows.
Nach Hardware
| RAM | Modellgröße | Beispiele |
|---|---|---|
| 32 GB | 30B (4bit) | Qwen3-Coder-30B |
| 48 GB | 31B (6bit) | GLM4.7-flash |
| 64+ GB | 31B (8bit) | GLM4.7-flash |
Für die aktuelle Macbook Generation ist meine Kaufempfehlung: 64 GB Ram reichen. Sprachmodelle, die nicht mehr komfortabel in 64 GB passen, sind ohnehin zu langsam für interaktives Arbeiten. Wichtiger als mehr RAM ist die Memory Bandwidth des Chips (M4 Max vs. M4 Pro).
Alternative: Zentraler Server statt Entwickler-Laptop
Nicht jeder Entwickler braucht ein maximal ausgestattetes MacBook. Eine Alternative für Teams ist ein zentraler LLM-Server.
Zum Beispiel den Mac Studio mit M3 Ultra. Er bietet bis zu 512 GB unified Memory bei ~819 GB/s Bandbreite. Damit laufen auch größere Open-Weight-Modelle (z.B. GLM 4.7 mit 358B Parametern), oder mehrere kleinere Modelle parallel. Der Stromverbrauch liegt unter 200 Watt. Für ca. 10.000 € ist ein solches Setup zu haben. Noch größere Modelle (wie z.B. Deepseek 3.2) können über ein Clustering von mehreren Mac Studios erreicht werden (exolabs).
LM Studio oder Ollama als Server einrichten, Entwickler verbinden sich über die lokale API (OpenAI und Anthropic Kompatibel).
Limitationen
Transparenz über die Grenzen dieses Benchmarks:
Der Test ist One-Shot only. Kein Tool-Use, kein Multi-Turn getestet. Bei Tool-Use gibt es sehr große Unterschiede zwischen Modellen: Manche generieren zuverlässig valides Markups und Diffs, andere produzieren regelmäßig Syntax-Fehler.
Die Qualitätsbewertung ist manuell. “Sehr gut” und “Gut” basieren auf visueller Inspektion, nicht auf automatisierter Validierung.
Ein Prompt ist nicht repräsentativ. Frontend-Entwicklung mit JavaScript ist nicht Backend, Datenanalyse oder Dokumentation.
Die Ergebnisse sind hardware-abhängig und gelten für Apple Silicon. Mit NVIDIA-GPUs wären die Zahlen anders.
Außerdem: Die Modell-Landschaft ist schnelllebig. Jeden Monat erscheinen neue Modelle.
Fazit
Qwen3-Coder-30B generiert ein funktionales Kanban-Board in 51 Sekunden. Für diesen Use Case liefern die besten lokalen Modelle nutzbare Ergebnisse.
MoE-Modelle zwischen 20 und 40 Milliarden Parametern bieten das beste Verhältnis von Qualität zu Ressourcenverbrauch. Sie laufen auf Hardware, die viele Entwickler bereits besitzen.
Für Teams mit Datenschutzanforderungen - ob NDA, Compliance oder regulatorische Vorgaben - sind sie oft die einzige Option.
Der Benchmark zum Selbst-Erkunden
Alle Ergebnisse sind im interaktiven Report verfügbar, mit sortierbaren Tabellen, Screenshot-Previews und Scatter-Plots:
Live-Report: michaseel.github.io/lmTestAuto
Repository: github.com/michaseel/lmTestAuto
Tools zum Einstieg
- LM Studio: lmstudio.ai
- Ollama: ollama.com
- Clustering mit Exolabs: exolabs.net
- VRAM Calculator: VRAM-Calculator
Quellen
[1] Hardware-Corner: First Nvidia DGX Spark LLM Benchmarks. https://www.hardware-corner.net/first-dgx-spark-llm-benchmarks/
[2] llama.cpp Discussion: Performance on NVIDIA DGX Spark. https://github.com/ggml-org/llama.cpp/discussions/16578
[3] MacRumors Forums: Mac Studio M3 Ultra LLM Performance. https://forums.macrumors.com/threads/mac-studio-m3-ultra-96gb-28-60-llm-performance.2456559/
[4] Evidently AI: 15 LLM Coding Benchmarks. https://www.evidentlyai.com/blog/llm-coding-benchmarks
[5] Hugging Face: BigCodeBench Leaderboard. https://huggingface.co/blog/leaderboard-bigcodebench
Footnotes
-
Open-Weight: Die trainierten Modellgewichte stehen zum freien Download bereit und können lokal ausgeführt werden – im Gegensatz zu proprietären Cloud-Modellen, bei denen nur die API zugänglich ist. ↩
-
GGUF (GPT-Generated Unified Format): Dateiformat für quantisierte Sprachmodelle, optimiert für CPU-Inferenz mit llama.cpp. ↩
-
MLX: Apples Open-Source-Framework für maschinelles Lernen auf Apple Silicon, optimiert für die Unified-Memory-Architektur der M-Chips. ↩